Deep learning is a subfield of artificial intelligence that has gained a lot of attention in recent years due to its ability to analyze and solve complex problems. It involves the use of artificial neural networks (ANNs), which are modeled after the structure of the human brain, to learn from vast amounts of data and improve its performance over time. Deep learning has revolutionized various industries, including healthcare, finance, transportation, and entertainment, by enabling machines to perform tasks that were once thought to be exclusive to humans.
In this article, we'll take a deep dive into the essential concepts of deep learning. We'll start by explaining artificial neural networks (ANNs) and their key components, such as neurons and activation functions. Then, we'll discuss the crucial algorithm for training ANNs, known as backpropagation, and explore multilayer perceptrons, which are ANNs used for pattern recognition. We'll also cover convolutional neural networks, which are widely used for image and video recognition, and recurrent neural networks, capable of processing sequential data. Lastly, we'll explore long short-term memory networks, a type of recurrent neural network that retains information for longer periods, and autoencoders, which learn efficient representations of data.
By the end of this article, you will have a clear understanding of the essential concepts of deep learning and how they are used to solve real-world problems. So, let's dive into the world of deep learning and explore its fascinating concepts.

Deep Learning is a sub-field of Machine Learning that has become increasingly popular in recent years. Its primary objective is to create intelligent machines that can learn from vast amounts of data. While it is often associated with neural networks, Deep Learning encompasses more advanced techniques, such as representation learning. In Deep Learning, data is represented as a layered hierarchy of concepts, where each layer builds on simpler layers, allowing for automated feature extraction.
Compared to traditional Machine Learning techniques that require expert knowledge in feature extraction and engineering, Deep Learning algorithms are more effective and scalable, making them highly suitable for handling large amounts of data. Deep Learning algorithms can perform better and require less user intervention if they comprehend the representations contained within the data itself. Deep Learning is an effective and scalable method for building intelligent machines that can learn from enormous volumes of data.
Let's now talk about some of the fundamental Deep Learning architecture and algorithmic terms.
Artificial Neural Networks (ANNs) are a type of machine learning algorithm that are modeled after the structure and function of the human brain. They are made up of networked nodes that process and send information, known as neurons. Pattern recognition, classification, and prediction are just a few of the activities that ANNs are utilized for.
An ANN's neurons are arranged in layers, with each layer processing data from the one before it. The data to be examined is delivered to the first layer, known as the input layer, while the final layer, known as the output layer, generates the outcome. One or more hidden layers that process the data and extract features important to the job at hand may be present in between.
During training, the ANN adjusts the strengths of the connections between the neurons to learn from the input data and produce the desired output. This process is often accomplished using an algorithm called backpropagation, which iteratively adjusts the weights of the connections in the network based on the errors between the predicted and actual outputs.
As a sort of machine learning algorithm, ANNs process and interpret data using interconnected neurons. They have a layered structure, with each layer processing data from the one before it. ANNs use the backpropagation technique to learn from input data and modify their connections to produce the desired output.
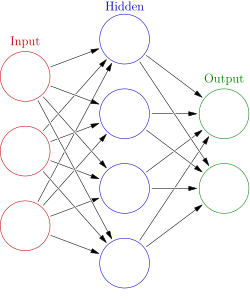 A typical artificial neural network
A typical artificial neural networkBackpropagation is a step in the neural network training process. To adjust the weights in the neural network layers, the error rate of a forward propagation is fed backward through the layers. The foundation of neural net training is backpropagation.
The algorithm for training artificial neural networks (ANNs) has two main stages: propagation and weight updates. During propagation, input data is forwarded through the network to generate output values, which are then compared to the desired output. The resulting errors are used to backpropagate and generate deltas at each neuron. During weight updates, weight gradients are computed and used to update the weights of the nodes. This process is repeated with multiple iterations until satisfactory results are achieved, often using optimization algorithms like stochastic gradient descent.
Multilayer Perceptrons (MLP) are a type of artificial neural network (ANN) that is widely used for supervised learning tasks, such as classification and regression. MLPs consist of multiple layers of interconnected neurons, with each layer processing information from the previous layer. The first layer is the input layer, which receives the input data, and the last layer is the output layer, which produces the final output of the network. The layers in between are called hidden layers, and they contain nonlinear activation functions that allow the network to model complex relationships between the input and output.
During training, an MLP adjusts the strengths of the connections between the neurons to learn from the input data and produce the desired output. This process is typically accomplished using an algorithm called backpropagation, which iteratively adjusts the weights of the connections in the network based on the errors between the predicted and actual outputs. MLPs can also use regularization techniques to prevent overfitting and improve their generalization performance on new data.
A convolutional neural network, also known as convnet or CNN, is a variant of the artificial neural network, which specializes in emulating functionality and behavior of our visual cortex. The following three elements are frequently present in CNNs:
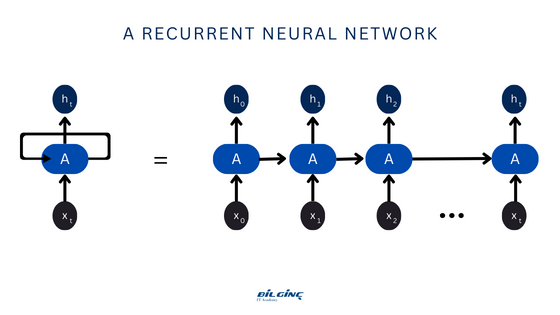
A recurrent neural network (RNN) is a type of artificial neural network in which connections between nodes can form a cycle, allowing the output of some nodes to influence the input received by other nodes in the same network. It can behave in a temporally dynamic way because of this. RNNs, which are descended from feedforward neural networks, can process input sequences of varying length by using their internal state (memory). They can therefore be used for tasks like speech recognition or unsegmented, linked handwriting recognition. Recurrent neural networks can handle arbitrary input sequences since they are theoretically Turing complete and can execute any program.
A sort of recurrent neural network called a long short term memory network is made to model complex, sequential data. By utilizing a technique known as gated recurrent units (GRUs), LSTMs are able to learn long-term dependencies in contrast to conventional RNNs, which are constrained by the vanishing gradient problem.
LSTMs, first developed by Hochreiter & Schmidhuber in 1997, are able to retain knowledge from extremely long sequences of data and avoid problems like the vanishing gradient problem, which frequently affects ANNs trained by backpropagation.
Autoencoders are a type of neural network used for unsupervised learning, where the goal is to learn a compressed representation of input data. The basic structure of an autoencoder consists of an encoder that maps the input data to a lower-dimensional space, and a decoder that maps the lower-dimensional representation back to the original data space. During training, the autoencoder learns to minimize the difference between the input data and the reconstructed data produced by the decoder. Data compression, anomaly detection, and feature extraction are common uses for autoencoders.

Deep learning is used in a wide range of applications, including:
These are but a few instances, and as technology advances, so do the possible applications for deep learning.
Introduction to Deep Learning Course
Python is a commonly used programming language in the field of deep learning. Many popular deep learning frameworks, such as TensorFlow, PyTorch, and Keras, have Python APIs and libraries that make it easier to build, train, and deploy deep learning models. Python is also a versatile language that is easy to learn and has a large and active community, making it a popular choice among developers and researchers in the field of deep learning.
In this course, you'll learn:
If you're interested in exploring the fascinating world of deep learning and machine learning, we invite you to enroll in our courses today! Our expert instructors are passionate about sharing their knowledge and guiding you on your journey to mastering these cutting-edge technologies. With a wide range of courses on offer, you're sure to find something that fits your interests and skill level. Don't miss out on this opportunity to expand your knowledge and boost your career prospects. Contact us now to learn more and enroll in our deep learning courses!